
Table of Contents
Introduction
While working on my SGDI exploratory project , I wanted something more robust over existing methods implemented by SpaceRacoon and HXChua .
By robustness, I intended my scraper to do the following:
- Run prediodically on a schedule
- Multi-threaded / Concurrency
For feature 1, this was necessary to be able to look at the SGDI across time. For example, movement of key senior personnel and reshuffling. While there may be limitations to the method, being able to document some movement would prove to be useful for other reasons not elaborated here.
For feature 2, being able to run concurrent scrapers and / or scrape in parallel would be very useful especially when the sitemap of the SGDI would be highly spread out and contain many sub-sites which could take a long duration. Coupled with the first feature, this would allow the scraping framework to be run quicker. A single-threaded scraper can only parse through one ministry at a time, as compared to a multi-threaded scraper which can parse through multiple ministries concurrently.
With knowledge of such requirements I narrowed down my choices to two big frameworks. First is the Scrapy library for web scraping. This was intentionally chosen over BeautifulSoup owing to its ability to support processing pipelines, crawl options and overcome some restrictions used to limit web scraping. More importantly, a scrapy task could be run by multiple workers concurrently. This meant that the concurrency requirement could be fulfilled easily without additional Multi-processing implementations which could be tricky.
The ability to schedule and monitor the crawling is a common need. While many libraries already offer integration with Scrapy such as ScrapeOps and SpiderMon , I wanted to integrate Scrapy with a larger data pipeline to be able to run other scripts/tasks (which may/may not be related to the webscraping) at the same time.
For this reason, I turned to Apache Airflow which is a (very) elaborate workflow scheduler. The webscraping task can be viewed as one workflow, out of others and the notion of task dependencies within workflows would be well documented. By task dependencies, I refer to the sequence of tasks that have to occur as part of the workflow. For example, if Task A precedes Task B and runs concurrently with Task C, Airflow can manage all these while providing very versatile options to retry failed tasks and document their failures.
One additional point was that both frameworks are written in Python which already has a rich ecosystem of analytics and data munging tools.
Implementation
In order to ensure that the solution can be run in most environments, containerization was used. A docker-compose file was created to specify the services we would be creating and exposing as web interfaces. The Airflow documentation already has a minimum example for such a use case. I simply added my scrapy service in addition to the one provided by the example.
For my scrapy service, I wanted it to be a web service that allows me to interact with my defined scrapy “spider”. A scrapy spider contains all the code needed to crawl a web target and parse data. I used Scrapyd which is a service daemon to run Scrapy spiders. This allows me to interact with my spider via a HTTP API, specifying stuff such as running it at a specified time, monitoring its progress and seeing what spiders are runnning at any given moment.
Here is a sample of my docker-compose file:
services:
sgdi-scraper:
build: ./govdb_scraper/
ports:
- 6800:6800
healthcheck:
test: ["CMD", "curl", "--fail", "http://sgdi-scraper:6800/"]
interval: 6000s
timeout: 10s
retries: 5
## Airflow stuff removed because its available on their website
Now, some of the airflow services can be overkill if this was a simple scheduler. For example, I could have done the whole scraping task as a cron job. However, I wanted to add other workflows to this project in the future, which would make this redundancy “rational” (or not?).
After running docker-compose and building the containers, my Airflow and scraping service is finally up!
Scheduling details
In Airflow, my scraping task is defined as a Directed Acyclic Graph (DAG) which is Airflow’s fancy way of saying a workflow. My DAG is represented in the image below:

Four tasks are specified:
scrapy_sgdi_check_health- Checks whether the Scrapy service is running, as the Scrapy service does abruptly exits sometimes and this check can be used to get the service back up if it is down.scrapy_sgdi_start_scrape- Starts the SGDI spiderscrapy_sgdi_check_running- Polls the ScrapyD endpoint to check if the task is actually running.scrapy_sgdi_check_done- Polls the ScrapyD endpoint to check if the task if completed. (Yes we could do it the other way round too.)
As part of the DAG definition, we can also define what to do if the task fails, succeeds as well as its frequency.
When that’s all defined, upon running our DAG, we get all these cool status reports out of the box:
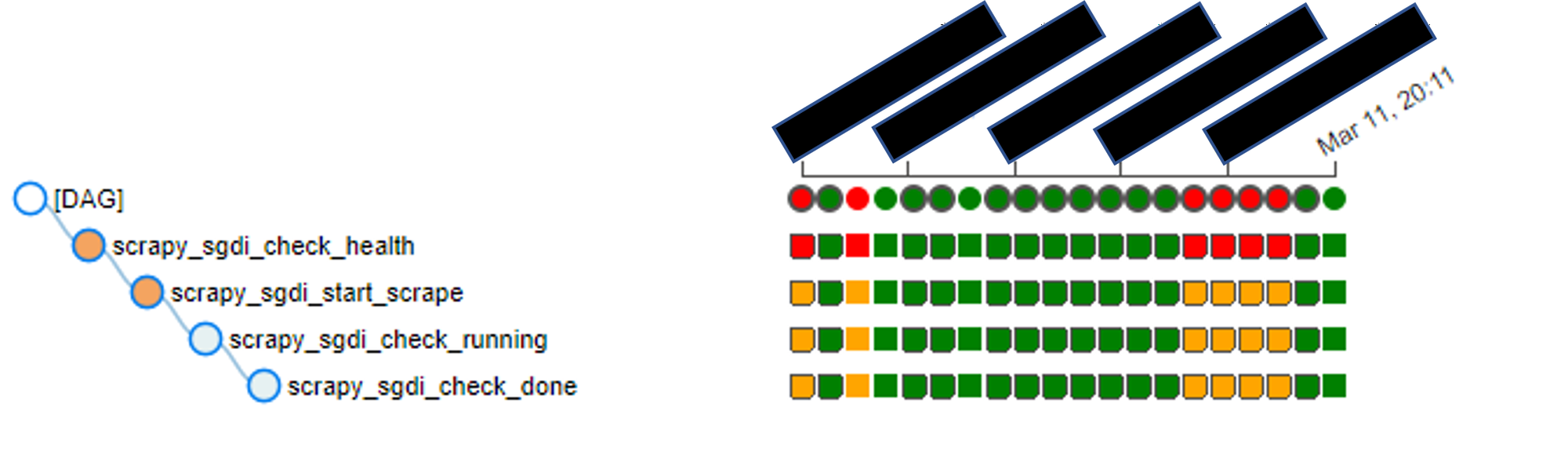
From the image above, we do see that there are times when the task fails and that’s clearly visible. It’s extremely helpful especially if you intend to do a “run and forget” approach. You can revisit the logs and check what and why things failed without writing any additional code!
Conclusion
I hope this post is helpful in understanding how to approach the issues around webscraping and offer another take on the problem!