- Published on
Lessons on running a 5 year scraping project
- Authors

- Name
- syamil maulod
Context (and Pain)
A while ago (3 years!), i wrote about automating a web scraper with airflow and scrapy in order to support my long running SGDI project. During that time, I was actually living in Netherlands while my entire setup was in Singapore. This brought about some interesting challenges in sustaining the scraper along with other services across vast geographic distances.
The entire setup is run on a small mini pc which i rescued from being sent to the dumpster. It is roughly 10+ years old by now! I host a number of services on it on top of the scraping operation. A diagram showing the operation can be viewed below.
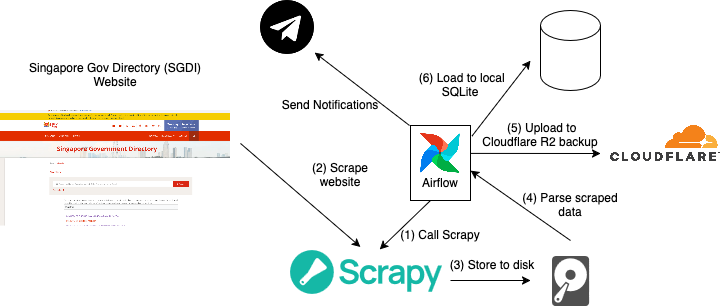
Here's a brief explanation of what's happening:
- An airflow DAG is defined with a task that sends a request to scrapy to start scraping
- Scrapy then scraps the website with some predefined heuristics
- The data is stored to disk as a csv.
- An airflow task then takes the csv, validates and parses it.
- In parallel the csv file is uploaded to a cloudflare R2 bucket as a backup
- The parsed data is loaded into a sqlite for analytics purposes.
For all the processes, notifications are sent via telegram:
In order to have remote access to my server without messing about with tunnels and stuff, i just used tailscale for all my devices (my other servers..) so i have one giant internal network without much hassle.
As I used airflow to schedule and monitor the various tasks, I could perhaps share some realities i faced while maintaining this project. Before that, i'm going to show you how the web scraping task performed over the years.
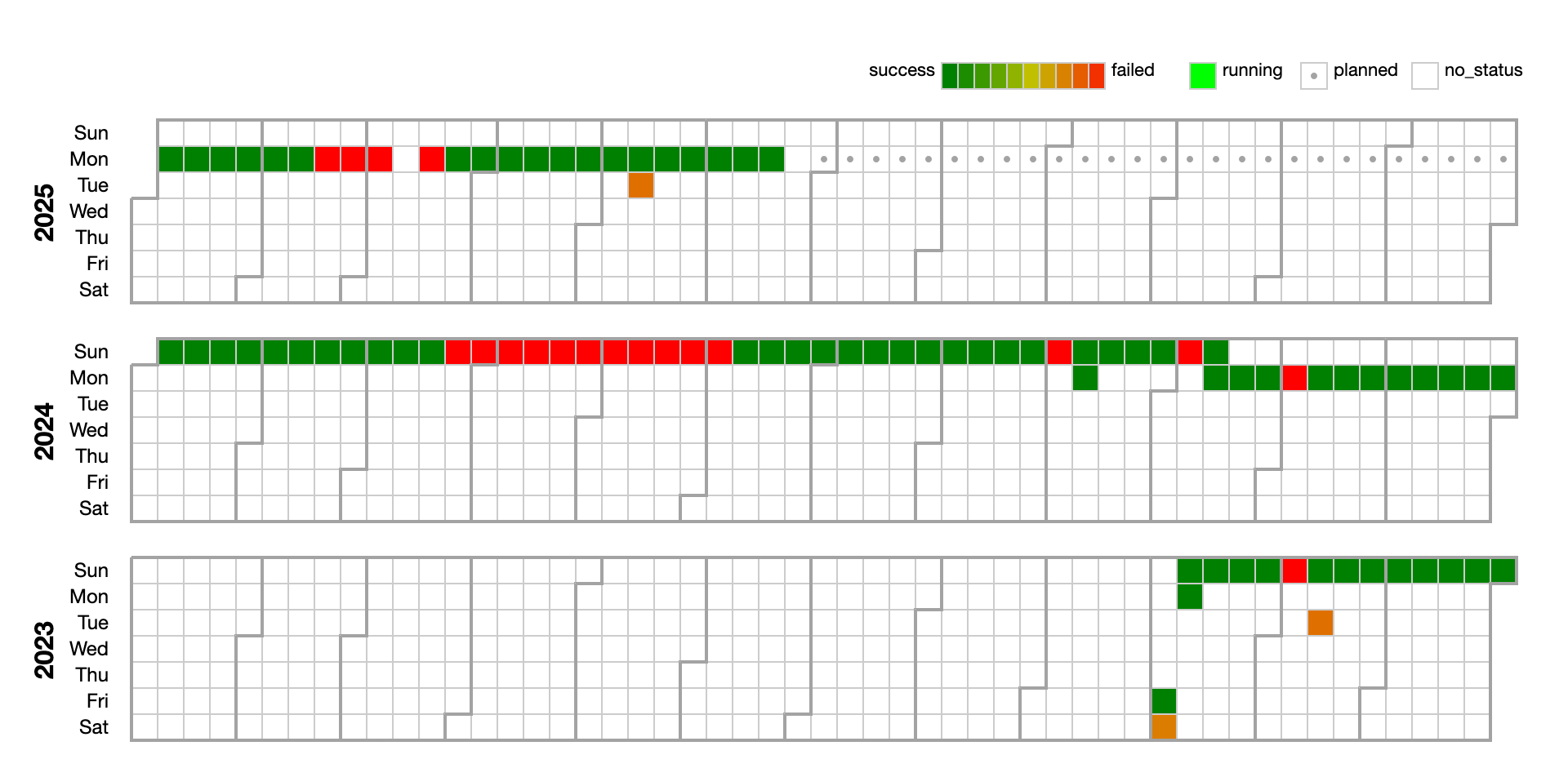
As you can see, it has quite a noticeable amount of failures (red) than successes (green). The reality is that the work is at the mercy of what I can control. Take for instance, the April to May period of 2024. It was red the whole time because the LAN cable attached to the server was loose! Being so far away from my setup (the server was located at my folks' place), I was left wondering what was the problem for a while until I asked my dad to take a photo of the switch. Lo and behold, the indicator of the port linked to the scraping server was out!
Also, other red moments were due to messed up system upgrades and such. All in all, i think the uptime is a measly 80%? Which, if it isn't obvious, means that its not so reliable.
Because of this, gaps in the SGDI scraping data remain, but I guess it isn't too mission critical.
Retrospective
Now after 5+ years in total of running this project, I'd like to take a moment to write about what i've learnt.
First, the SGDI project seemed like a simple question: How can we understand the public service organisation?
To do so, I had to pick up the following skills:
- Web scraping
- Database management
- Python and Javascipt among others
- Docker
- Linux knowledge
- Interfacing with web apis
- Graph databases
- along with optional stuff such as transformers, text analytics, etc.
These were not quite apparent at the start, and it was pretty intimidating considering that I was working on a pretty niche topic, with not much interest from anyone but myself (i think).
Honestly, there was plenty of cross pollination between these skills and my career. It made me understand technical debt and provided a solid base for data engineering in general.
Crucially is that I learnt to work with resources that I had to make things work. The whole "learning to learn" experience is kinda the crux of it. You start off with a question, and then go just enough down the rabbit hole to get out and get things done. Another key thing is functional decomposition.
Simple questions can lead to complex architectures.
If I look at the diagram above, its not that difficult right? But to get there you kinda have to make them available in the first place and before that you kind of have to see it in the context of the system you are trying to build.
You should be asking, for each functional component:
- What are the alternatives?
- How maintanable is this approach?
- How robust is it?
- How does it integrate with the rest of the system?
Take for example, the decision to output the data as a csv. Now, csv has no data integrity checks nor does it have any form of data compression to optimize disk space. However, i chose csv because can be easily inspected, and can be read by most decent languages without any additional libraries.
Functional decomposition is a great process when dealing with complex systems. It also fits in many definitions of complexity where primitive components interact with each other to accomplish an elaborate system-level goal. What can be a daunting question, just needs a moment or two to step back and ask the what questions before the how questions come in.
SGDI project and beyond
The SGDI project is a long term data science project and it requires some persistence and determination. Based on the experiences I had so far in architecturing and operationalizing the vision, I do think its worth it to continue and now it should now move on to its primary goal of asking questions about the organisation of the singapore public service.
Bonus: SGDI analytics
A tool to explore SGDI data is available here. Due to the sensitive nature of the data, prospective users should drop me a line - Contact